Miscellaneous
How AI Is Revolutionising Our Work
Explores how AI boosts workplace productivity and creativity by automating tasks, aiding idea generation, and empowering professionals to work more …
TL;DR; Switching from Hugo’s basic related content feature to an AI embeddings-based approach enabled much more accurate and meaningful content recommendations, improving both user navigation and AI discoverability. The solution was cost-effective, scalable, and reduced computational overhead by caching similarity scores and storing embeddings for reuse. Development managers can consider using AI embeddings for smarter content linking, which can enhance user experience and support future automation or classification needs.

Mid-last year, I transitioned my website to Hugo and since then have been exploring AI-driven content classification. A common feature I have always appreciated is the “related content” recommendation, suggesting to readers what’s next or what else might be of interest. Although Hugo’s built-in related content functionality is perfectly serviceable, relying on parameters like tags, keywords, and headings, I believed there was room for something more sophisticated.
In general, for my site, my focus has shifted towards Generative Experience Optimisation (GEO), aiming to enhance the reading experience for both humans and generative AI agents. Unlike traditional Search Engine Optimisation (SEO), GEO optimises content readability and semantic relevance, creating a win-win scenario for both humans and AI. SEO often prioritises keyword density, sometimes compromising readability. GEO, conversely, optimises content clarity for both human understanding and AI comprehension. With this shift, the standard method in Hugo,though efficient for basic needs,felt insufficient.
The challenge was clear: Hugo’s built-in related content system, based on static parameters, lacked semantic understanding. It didn’t recognise deeper contextual relationships between articles beyond shared tags or keywords.
I initially considered leveraging my existing classification capabilities, but the computation involved would be excessive, approximately 2.56 million API calls for my content catalogue, an impractical approach that would be very expensive and slow.
Instead, I opted for a more fun, computationally efficient method: OpenAI Embeddings. Embeddings convert textual content into numerical vectors, capturing semantic meaning and enabling sophisticated comparisons.
The power of embeddings lies in their semantic understanding. Rather than purely lexical comparisons, embeddings identify relationships in meaning. This makes them perfect for establishing truly relevant connections between articles.
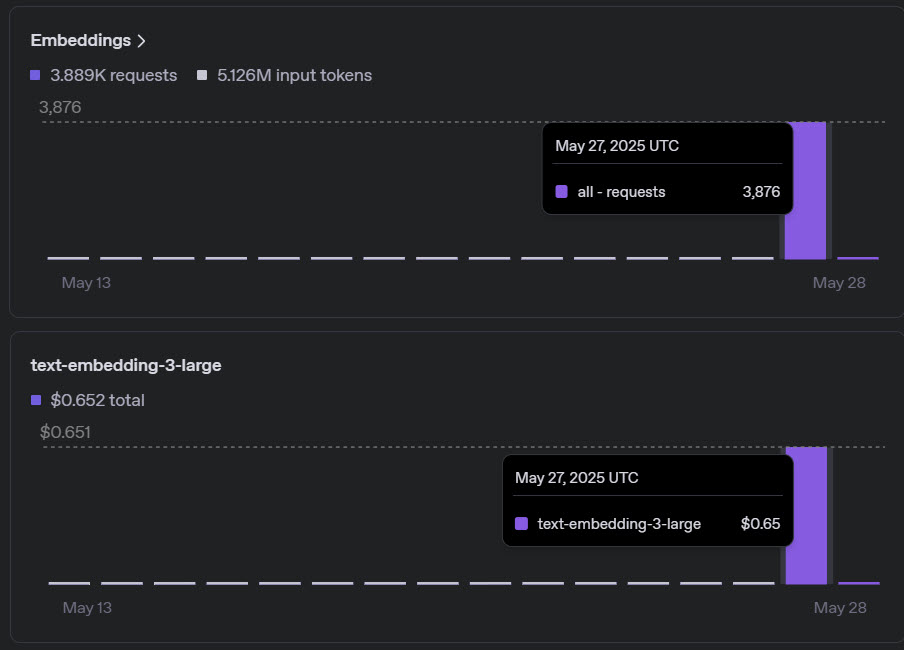
The first step was to generate embeddings for each piece of content using OpenAI’s Embeddings API. The cost-efficiency of this method was striking; I generated embeddings for around 1,600 content pieces (about 3,876 requests, including debugging) at a minimal total cost of $0.66.
1function Get-OpenAIEmbedding {
2 param (
3 [Parameter(Mandatory)]
4 [string]$Content,
5
6 [string]$Model = "text-embedding-3-large",
7 # OpenAI API Key
8 [string]$OPEN_AI_KEY = $env:OPENAI_API_KEY
9 )
10
11 $response = Invoke-RestMethod `
12 -Uri "https://api.openai.com/v1/embeddings" `
13 -Headers @{
14 "Authorization" = "Bearer $OPEN_AI_KEY"
15 "Content-Type" = "application/json"
16 } `
17 -Body (ConvertTo-Json @{
18 input = $Content
19 model = $Model
20 }) `
21 -Method Post
22
23 return $response.data[0].embedding
24}
To manage these embeddings efficiently, I stored them locally and synced them to Azure Blob Storage, creating a reusable, easily accessible repository. Although the cost was minimal the runtime to get the embedding for 1600 items was non-trivial so I syncing them to cloud storage to significantly reduces processing time for future operations.
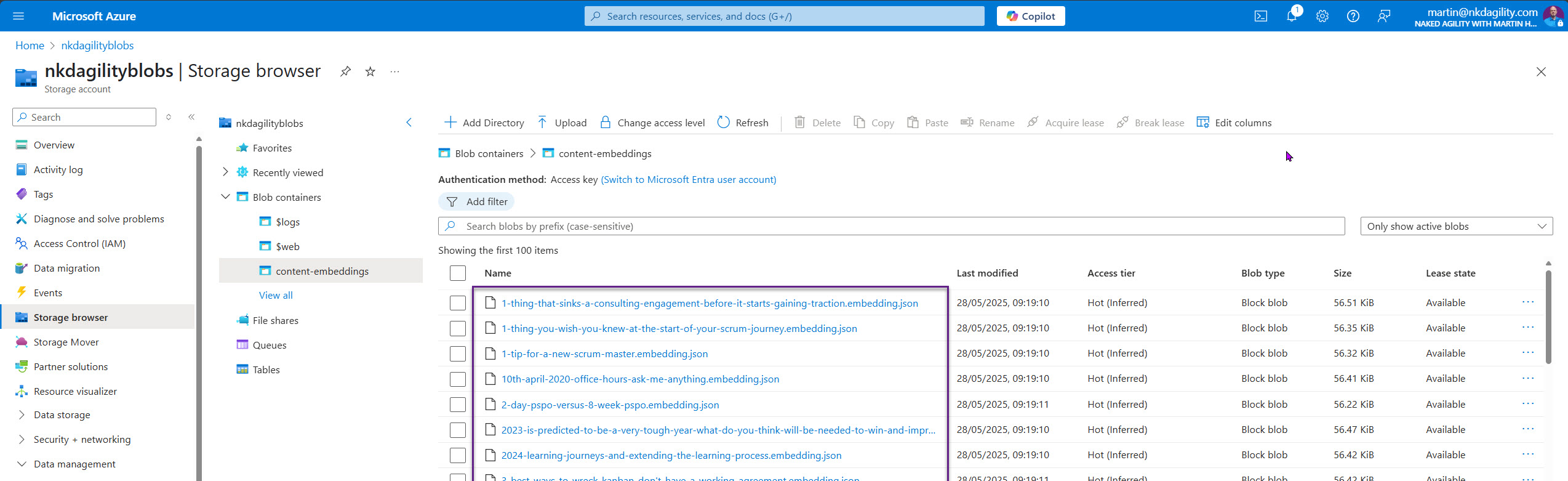
AZCopy is your friend here as it’s able to minimise the upload/download time.
With the embeddings in place, the next task was to calculate the semantic similarity between content items using Cosine Similarity. This algorithm measures the angle between two embedding vectors, returning a similarity score ranging from -1 (completely opposite) to 1 (identical).
1function Get-EmbeddingCosineSimilarity {
2 param (
3 [float[]]$VectorA,
4 [float[]]$VectorB
5 )
6
7 $dotProduct = 0
8 $magnitudeA = 0
9 $magnitudeB = 0
10
11 for ($i = 0; $i -lt $VectorA.Length; $i++) {
12 $dotProduct += $VectorA[$i] * $VectorB[$i]
13 $magnitudeA += [Math]::Pow($VectorA[$i], 2)
14 $magnitudeB += [Math]::Pow($VectorB[$i], 2)
15 }
16
17 if ($magnitudeA -eq 0 -or $magnitudeB -eq 0) {
18 return 0
19 }
20
21 return $dotProduct / ([Math]::Sqrt($magnitudeA) * [Math]::Sqrt($magnitudeB))
22}
This step was computationally intensive due to comparing each content item against all others. To manage this, I cached similarity scores above a threshold (0.5 or higher), significantly reducing future computations.
1{
2 "calculatedAt": "2025-05-27T18:44:01.8272803Z",
3 "related": [
4 {
5 "Title": "Mastering Azure DevOps Migration: Navigating Challenges, Solutions, and Best Practices",
6 "Slug": "mastering-azure-devops-migration-navigating-challenges-solutions-and-best-practices",
7 "Reference": "resources/videos/youtube/_rJoehoYIVA",
8 "ResourceType": "videos",
9 "ResourceId": "_rJoehoYIVA",
10 "Similarity": 0.6808168645512461
11 },
12 {
13 "Title": "Mastering Azure DevOps Migration: A Step-by-Step Guide for Seamless Project Transfers",
14 "Slug": "mastering-azure-devops-migration-a-step-by-step-guide-for-seamless-project-transfers",
15 "Reference": "resources/videos/youtube/Qt1Ywu_KLrc",
16 "ResourceType": "videos",
17 "ResourceId": "Qt1Ywu_KLrc",
18 "Similarity": 0.6715379090446947
19 },
20 {
21 "Title": "Navigating the TFS to Azure DevOps Migration: Overcoming Compatibility Concerns with Confidence",
22 "Slug": "navigating-the-tfs-to-azure-devops-migration-overcoming-compatibility-concerns-with-confidence",
23 "Reference": "resources/videos/youtube/qpo4Ru1VVZE",
24 "ResourceType": "videos",
25 "ResourceId": "qpo4Ru1VVZE",
26 "Similarity": 0.6701177401809448
27 }
28 ]
29}
This is then stored with the content item and used to get the related content items for any specific content item.
With similarity scores computed and cached, integrating them into Hugo was straightforward. I updated the Hugo layout to dynamically load the cached similarity scores at build-time, displaying the top 3 related content items for each article. This provided a more meaningful user experience without excessive runtime overhead.
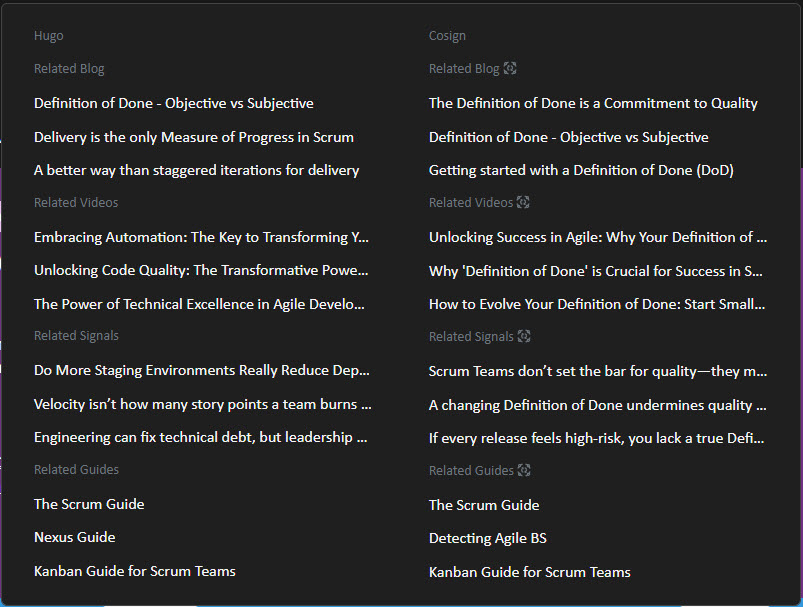
The impact of this all remains to be seen, but there is an expectation that beyond the usability enhancements that this brings for human readers, it will also bring enhancements to content analysis by AI agents. These links enable the discoverability of other actually related content which should tickle the AI search algorithms to promote the content more.
The implementation was remarkably successful:
As I mentioned, the impact remains to be seen, and I have no idea how often AI crawls the content for updates. However, this will be live on my site by the time you read this.
If this experiment proves to be successful, there are a number of other ideas that I have for its use:
Using embeddings to enhance related content has provided a practical and scalable improvement to my site’s content classification. It aligns perfectly with my goal of optimising the experience for both human readers and AI systems. While the true impact of this approach will become clearer over time, the initial implementation already shows significant promise for improving relevance and efficiency.
Each classification [Concepts, Categories, & Tags] was assigned using AI-powered semantic analysis and scored across relevance, depth, and alignment. Final decisions? Still human. Always traceable. Hover to see how it applies.
If you've made it this far, it's worth connecting with our principal consultant and coach, Martin Hinshelwood, for a 30-minute 'ask me anything' call.
We partner with businesses across diverse industries, including finance, insurance, healthcare, pharmaceuticals, technology, engineering, transportation, hospitality, entertainment, legal, government, and military sectors.

Lockheed Martin

Alignment Healthcare
Genus Breeding Ltd

Milliman
Brandes Investment Partners L.P.

Flowmaster (a Mentor Graphics Company)

Emerson Process Management

Hubtel Ghana

Bistech

New Signature

MacDonald Humfrey (Automation) Ltd.
Epic Games

Boeing

Lean SA

Teleplan

Ericson

Trayport

Higher Education Statistics Agency
Department of Work and Pensions (UK)

New Hampshire Supreme Court

Washington Department of Enterprise Services

Nottingham County Council

Washington Department of Transport
Royal Air Force
New Signature

Slaughter and May
Brandes Investment Partners L.P.

Freadom
Hubtel Ghana
Bistech